This is the behind-the-scenes journey of creating Tynker Copilot, our groundbreaking innovation designed to help kids learn to code faster. Imagine a world where a simple text prompt transforms into a fully-fledged Tynker program, powered by visual code blocks. Intrigued? Read on to discover how we built it!
Here are a few such examples generated by Tynker Copilot.
| Prompt | Response |
|---|---|
| “make codey appear in random spots on the stage” |  |
| “use the left and right keys to move the puppy” | 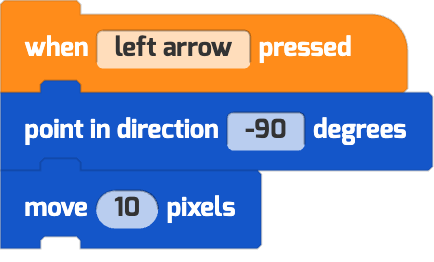 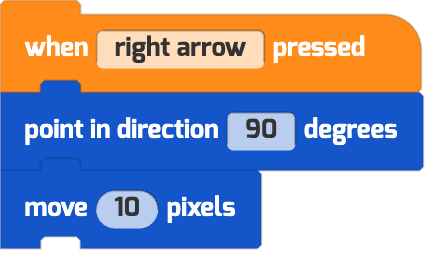 |
| “make the puppy run towards my mouse” | 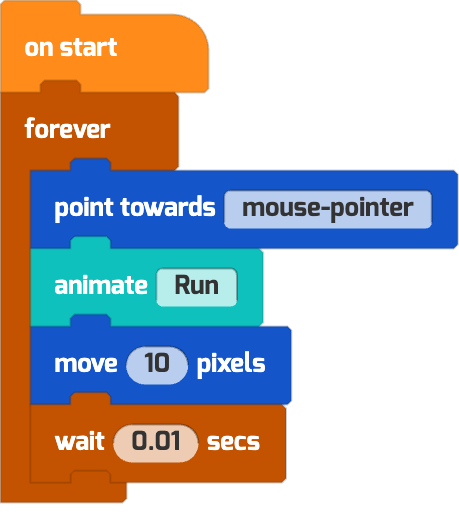 |
| “make the monster eat and then slowly grow bigger” | 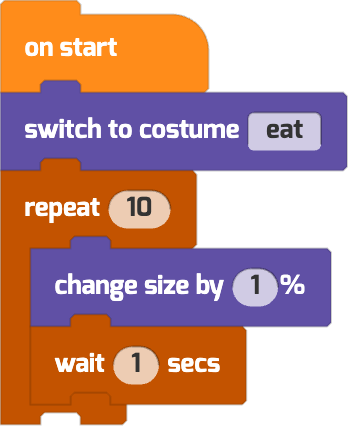 |
Unlike traditional text-based coding languages like Python or Java, visual block coding platforms like Tynker, Scratch, MakeCode, and Snap operate at a higher level of abstraction. They often transcend standard programming constructs like loops and conditionals. For example, a single block like “move n pixels” could equate to 20 lines of C code. Beginners would need to navigate the intricacies of graphics libraries, variable tracking, and angular calculations to achieve the same result. While there are several Large Language Models (LLMs) focused on coding—such as OpenAI’s Codex, Salesforce CodeGen, Replit’s Ghostwriter, Meta’s Code Llama, and Google’s Codey—their training data is sourced from developer code repositories and websites, making them less suited for the unique challenges of visual block coding.
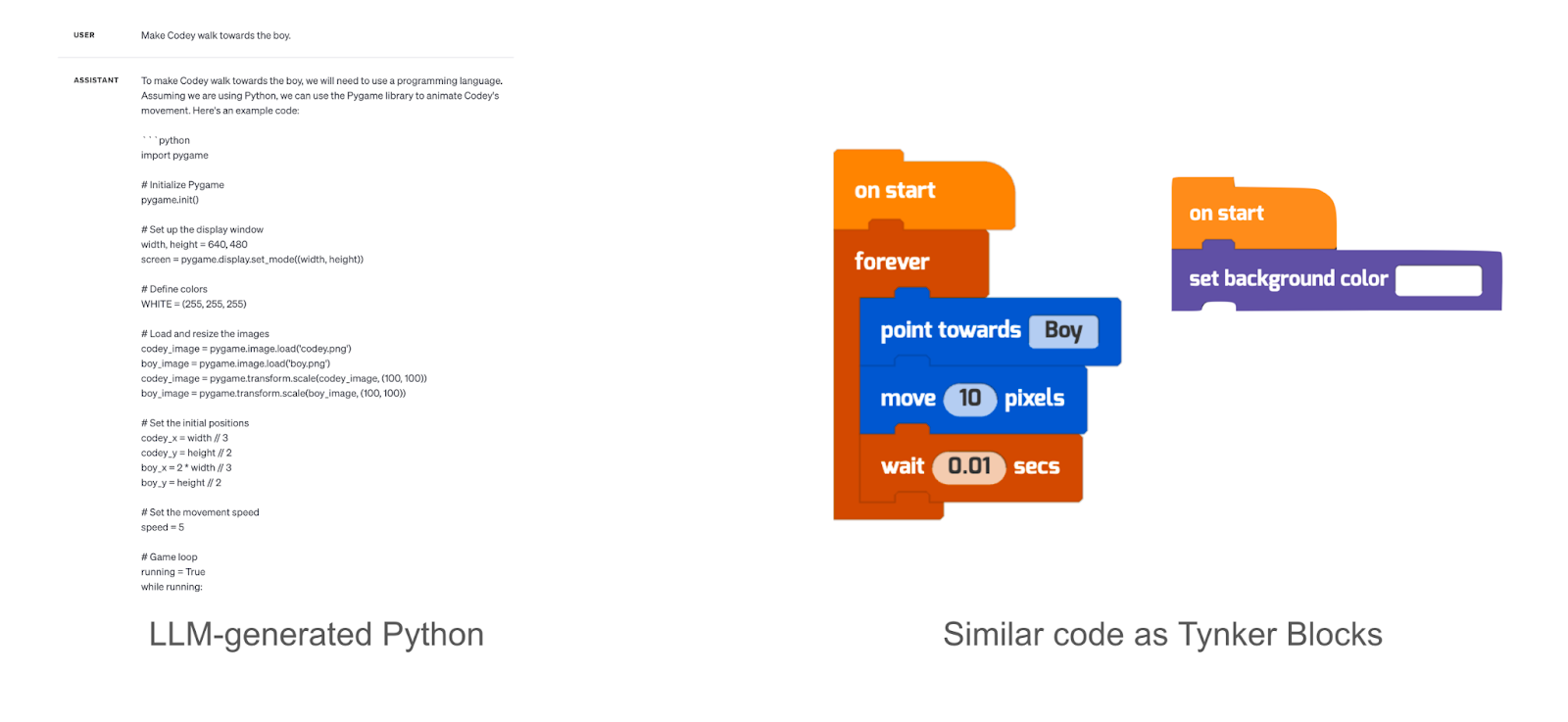
Table of Contents
Our Initial Experiments with Transformer Models
Harnessing the power of the transformer model architecture, which gained prominence through the BERT language model in 2018, we took a groundbreaking step. We trained a model specifically designed to autocomplete the next block of code in a Tynker visual block coding project. The secret sauce? Our expansive repository of millions of user-published projects. This treasure trove of data provided the fuel that transformer models crave for training, enabling us to offer real-time block suggestions as students craft their projects.
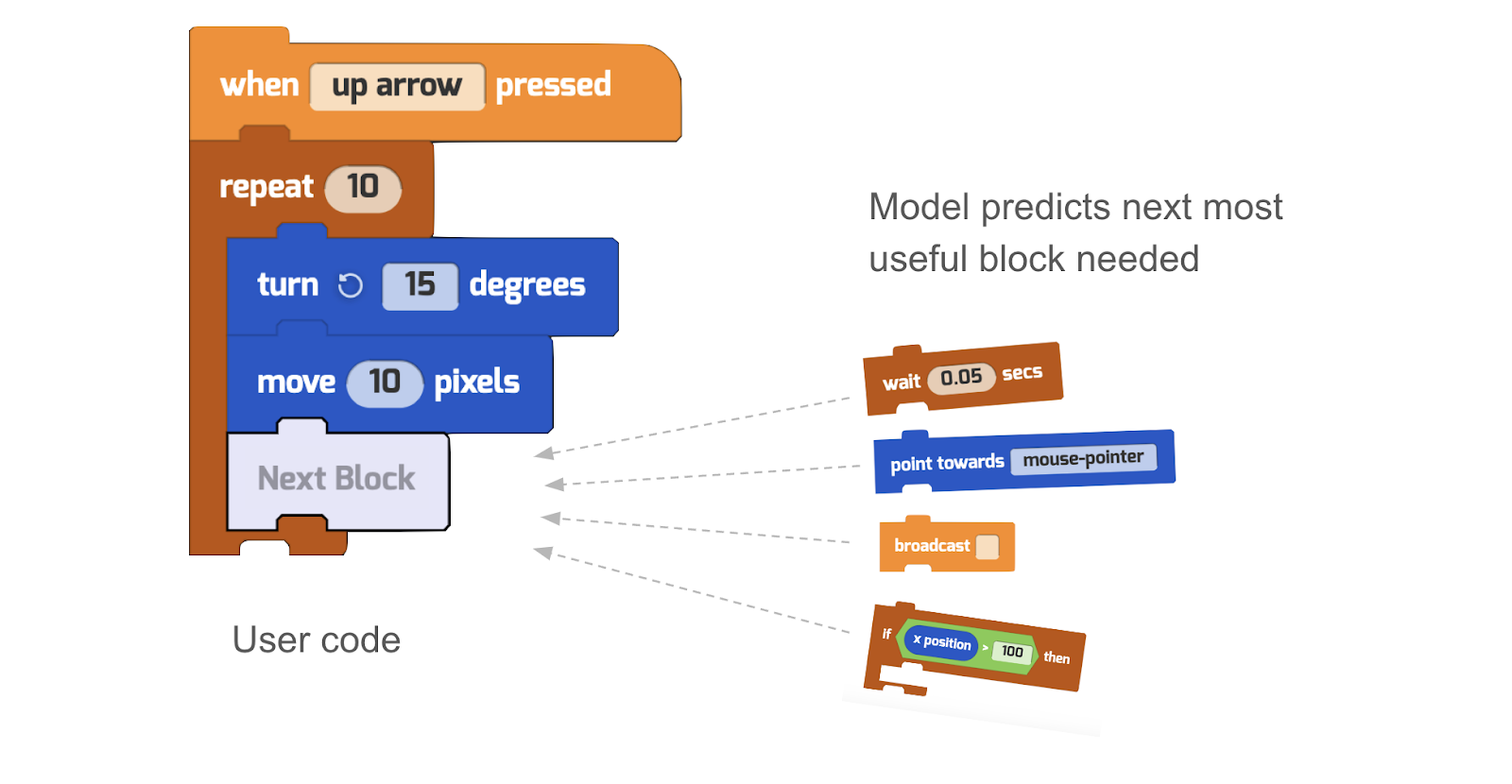
Predict the next block to assist while coding
One big hurdle we encountered was the ‘cold start’ problem for coding beginners, particularly young learners who had no prior exposure to block coding. How could we guide them to intuitively select the right starting blocks and relevant code for their unique projects? The answer lies in the future integration of Large Language Models (LLMs). Soon, students will be able to simply speak or type their intentions, thereby automatically generating the appropriate code blocks and transforming the coding experience into something as intuitive as casual conversation.
Fast Forward to LLMs in 2023: Elevating Tynker’s Learning Experience
Inspired by the recent advancements demonstrated by ChatGPT, we set our sights higher, aiming to create a more robust learning aid. Our goal? To help kids effortlessly translate their ideas into code, understand any given code’s functionality, and provide real-time debugging assistance.
In our initial experiments, we aimed to guide ChatGPT into generating block-like code that could be converted into Tynker’s native coding language. While this strategy showed some promise, our foremost concern remained student privacy, given that it involved transmitting student-generated prompts to an external service.

First Approach: ChatGPT with prompting to generate block-like code
Recognizing the need for enhanced privacy, we began investigating open models and Large Language Models (LLMs) that could be fine-tuned and deployed within our own secure server infrastructure.
Using Llama 2 with Fine-Tuning
To address the critical issue of student privacy, we opted for Meta’s groundbreaking Llama2 base chat model, fine-tuning it to meet Tynker’s specialized visual coding requirements. Our unique coding language, tailored for young learners, encompasses a wide range of features—from parallel scripts and multiple sprites to specialized libraries for animation, music, physics, AR, and even Minecraft modding.
Training a model on a visual coding language presented its own set of unique challenges. Beyond mastering the syntax of block language, we needed a comprehensive dataset that would capture the kinds of prompts kids are likely to input. These often include high-level ideas or actions not typically found in traditional text-based coding datasets. For instance, a prompt like “make Codey walk towards the boy” in OpenAI’s Codex playground generates complex code that could overwhelm beginner programmers.
Complex code will overwhelm beginners
In the absence of any publicly available dataset tailored for this purpose, we leveraged fine-tuning techniques and the pre-trained capabilities of the Llama2 model to dramatically reduce the size of the training data needed—from millions of samples to just thousands. Hosting the model on our own secure cloud servers further allows us to prioritize student privacy, aligning with our commitment to creating a safe and educational coding environment.
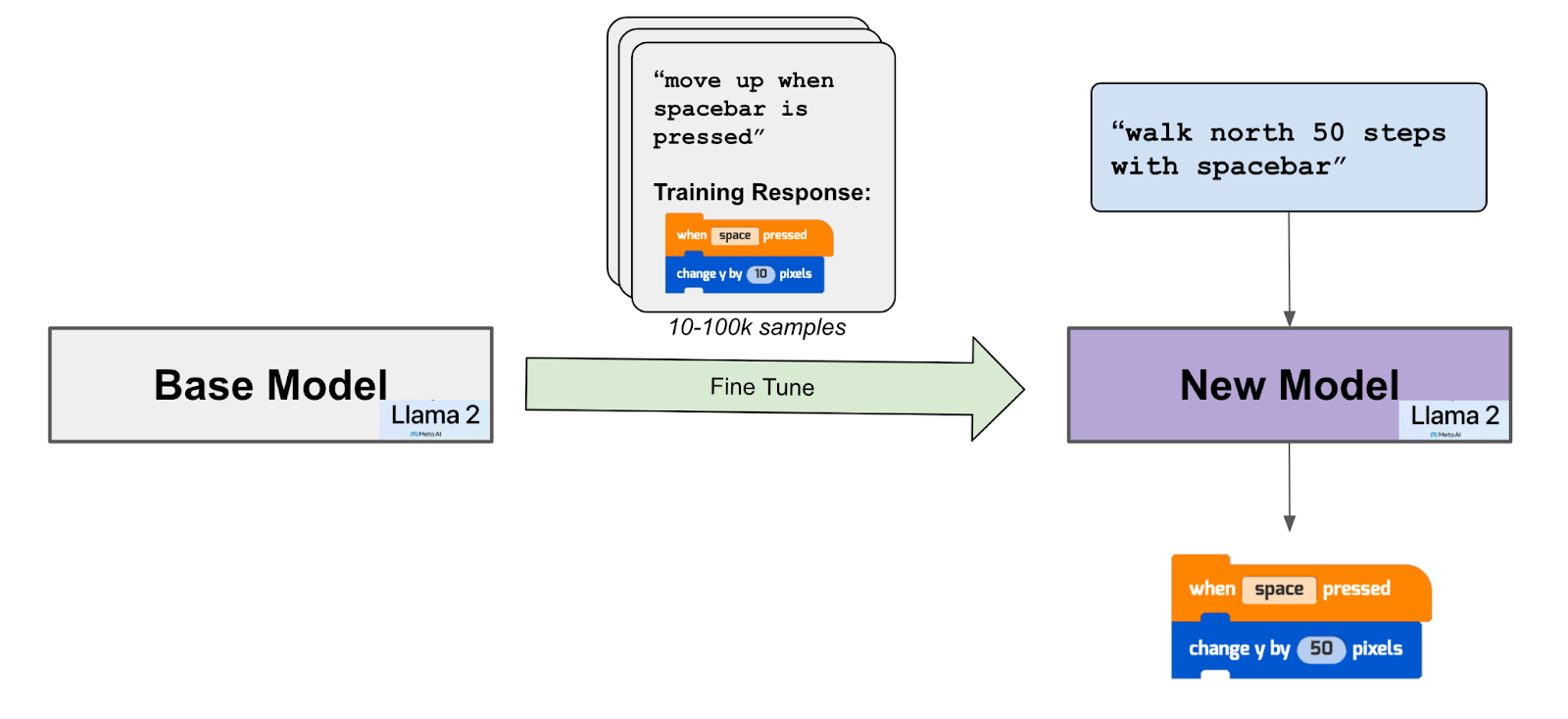
Fine-tuning Llama 2 with block code
Our initial challenge in this data-driven endeavor was to translate Tynker’s visual language into a format that machine learning models could comprehend. We started with a straightforward approach, encoding project data as JSON text. Given that Tynker programs are essentially Abstract Syntax Tree (AST) structures, they can be readily stored in this format. In this schema, various nodes in the tree correspond to function calls. For example, a simple expression like “a + b” would be represented in JSON as {“function”:”valueOpBinary”, “args”:[“a”, “+”, “b”]} and then converted into a function call such as valueOpBinary(“a”, “+”, “b”).
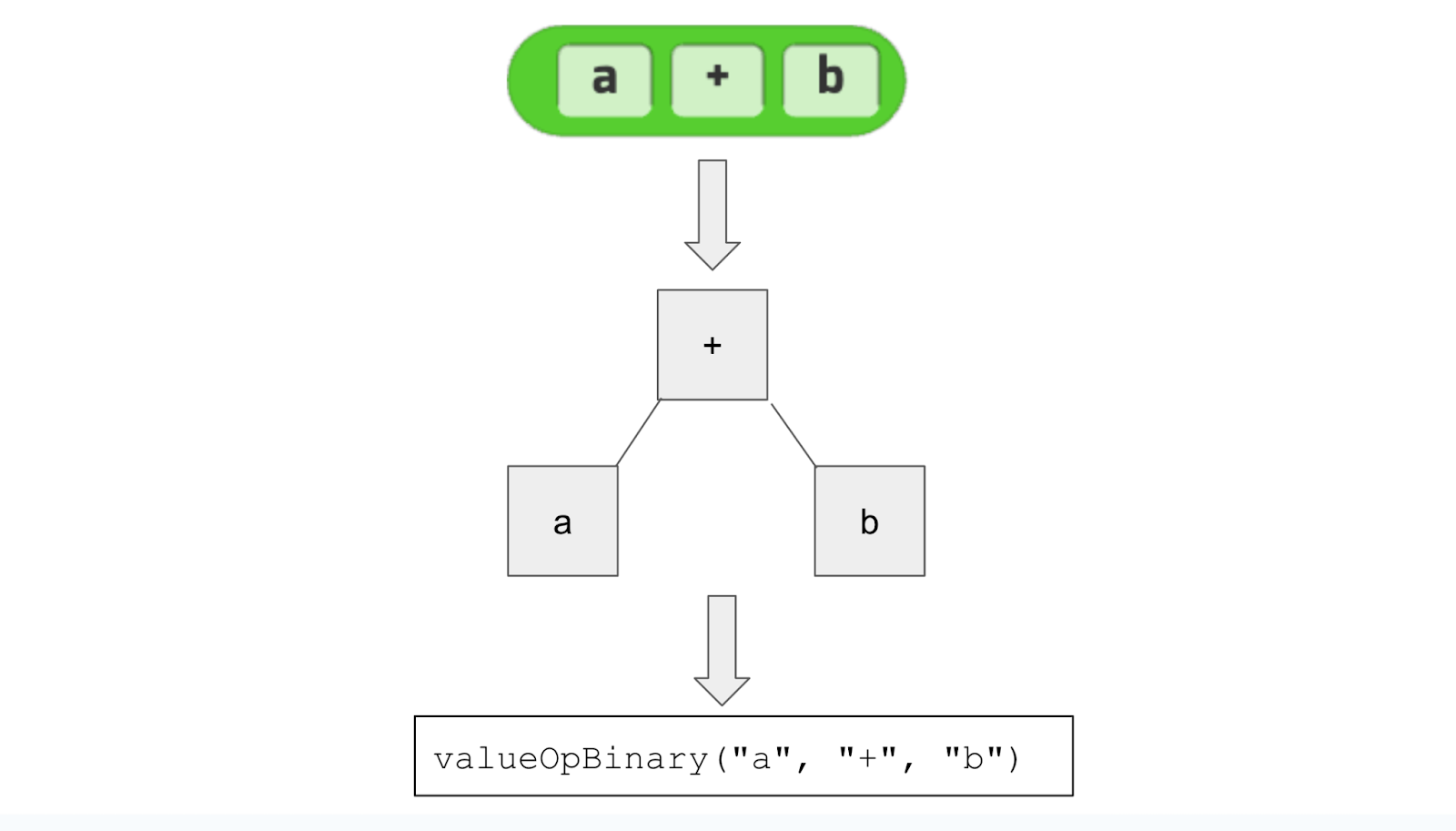
Tynker Block Code as Abstract Syntax Tree
Training large models is no small feat; it’s a resource-intensive process that demands significant computational power. In our initial code completion experiments, we trained models from scratch, initializing their weights randomly and feeding them millions of data samples multiple times to optimize these weights. Fine-tuning, which involves optimizing all layers of the network, is equally demanding. Traditional methods could take days or even weeks to train even a small model. To navigate this challenge efficiently, we turned to a popular, parameter-efficient technique known as LoRA (Low Rank Adaptation), enabling us to fine-tune the model without requiring hundreds of GPUs and in a more manageable timeframe.
The LoRA technique essentially “locks in” the pre-trained weights while introducing two smaller matrices that approximate the behavior of the larger model, as if it had been fully fine-tuned. This results in fewer weights requiring modification during the backpropagation process. To optimize resource usage even further, we employed QLoRA (Quantized LoRA), a more memory-efficient variant that reduces the bit representation of the weights. This efficiency enabled us to conduct experiments using Google’s Colab, a platform ideal for low-cost or even free experimentation with access to GPU resources and Google Drive for data storage. Utilizing this setup, we successfully loaded the Llama2 model weights into an Nvidia T4 16GB GPU for training.
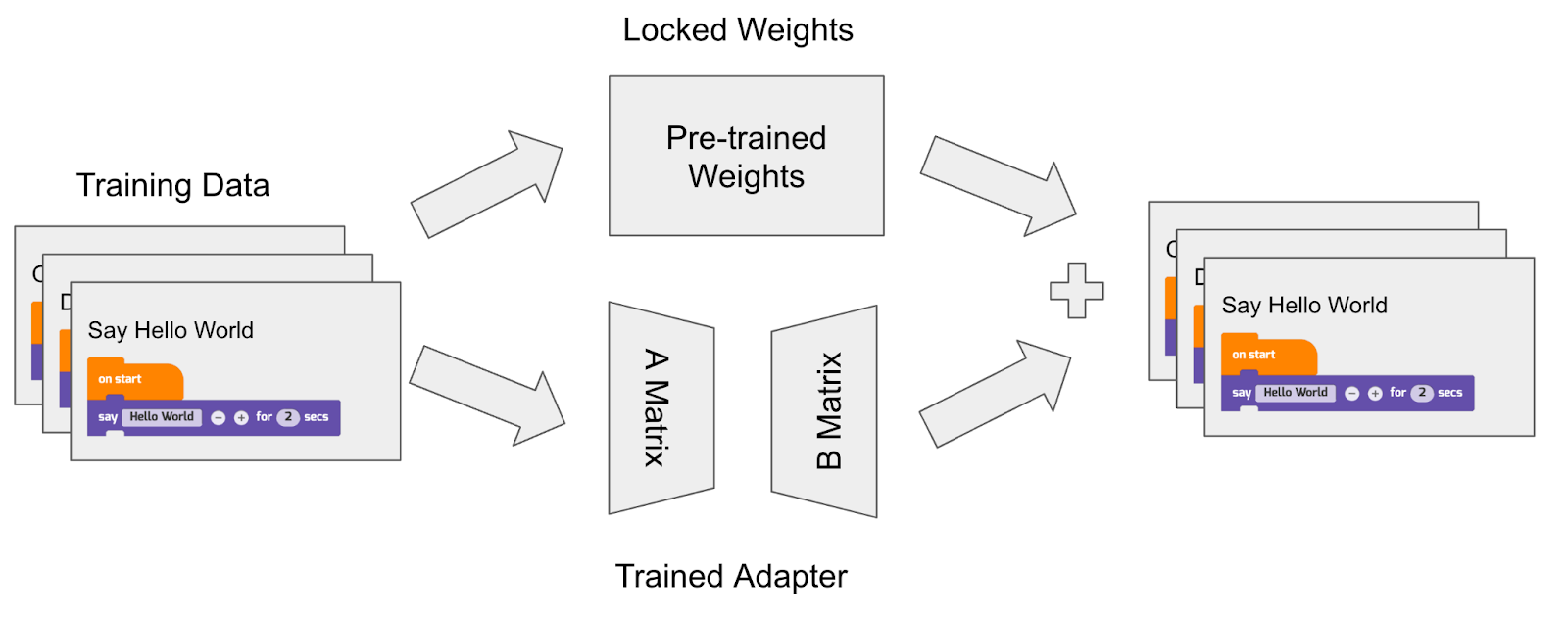
Performance Improvement with Low Rank Adaptation
For our foundational model, we opted for the Llama2-7B instruction-following chat model, utilizing the transformer and PEFT (parameter-efficient fine-tuning) libraries. The QLoRA and training libraries offer a myriad of adjustable parameters, requiring multiple training iterations to pinpoint the optimal settings for our specific needs. Using QLoRA, we managed to process around 1,000 training samples in just 4 hours. Post fine-tuning, we obtained a compact 150MB adapter file, a stark contrast to the original 13GB model file. These weights were then integrated into the base model, and we generated several quantized versions with varying bit precisions using the llama.cpp project. The end result was a manageable 4GB model file, capable of running inferences on our M1 MacBooks at an impressive speed of approximately 20 tokens per second. This efficiency opens up exciting possibilities for integrating such a model into our mobile Tynker app.
Our initial results were promising. Starting from a point where the model had no knowledge of Tynker blocks or their functionality, we successfully generated working code from simple prompts like “ask for my name and greet me.” However, the model faced difficulties with more intricate prompts, leading to issues like hallucinating non-existent blocks and introducing new, incompatible syntax. The parameters for our function calls were occasionally reordered, adding another layer of complexity. Clearly, we had multiple avenues to explore for improvement.
| drawing = blockPenDrawStarWith5Points(points[:]) |
How We Enhanced Model Performance
Upgrading to Llama 2 – 13B
Our transition to the Llama2-13B chat model marked a significant upgrade. While this upgrade meant we outgrew the capabilities of free Google Colab resources, we seamlessly migrated our work to Google’s Vertex AI platform, where we utilized managed Jupyter notebooks. This allowed us to effortlessly scale our operations, first by deploying multiple T4 GPUs and later by harnessing the incredible power of A100 GPUs.
Minimizing Hallucination with an intermediate Tynker language
We suspected that the Llama2 model’s syntax mix-ups originated from its pre-training on diverse code samples, including Python and JavaScript. Rather than stripping Llama2 of its valuable data and retraining it, we innovated. We developed an intermediate Tynker language that closely aligns with text-based coding languages, yet retains the user-friendly nature of our visual language.
Leveraging Public Repositories to Broaden the Training Set
Publicly available data sets from repositories like Hugging Face offer a plethora of well-annotated code samples in text-based languages such as Python, JavaScript, and C++. These languages often share core programming constructs—think “if” statements, “while” and “for” loops, and assignment expressions like “a = 100.” To harness this rich data, we needed to translate it into Tynker’s unique block code format.
To achieve this, we employed transpilers, specialized tools that parse code from a source language and compile it into a target language. In our case, the target was Tynker’s block code. While not every piece of syntax was directly translatable, we carefully curated the sample set to include only code that could be logically represented in a block coding environment, thereby enhancing the Tynker coding experience.
Leveraging Tynker’s rich data sources
Tynker boasts a wealth of educational content including hand-crafted courses, lessons, projects, and tutorials. Coupled with teacher guides and help references, this allows us to continually enrich our training samples. Additionally, what sets us apart is our repository of student-published projects ( millions of apps, games and mods) user community, one of the world’s largest repositories for block coding projects. Each user-published project undergoes rigorous vetting by our moderation team, who not only filter out objectionable content but also label and annotate each project for future use. While we haven’t tapped into all of this data goldmine yet, it holds immense potential for future fine-tuning and enhancements.
Scaling on Demand
With an enriched dataset of thousands of high-quality training samples, our model training has reached new heights of efficiency. Utilizing a single A100 GPU with 40GB memory, we’ve reduced the training time to just 10 hours, peaking at a memory utilization of 35GB. Our fine-tuned models are securely hosted on AWS, offering us the flexibility to scale from G5-class A10 GPUs to more powerful p4d instances equipped with A100 GPUs. The inference speed of our 13B model clocks in at an impressive 50 tokens per second on a modest GPU. This efficiency allows us to fine-tune our models regularly, ensuring they stay up-to-date with the latest trends and topics in our vibrant project community.
The Result
Our advanced model is now adept at turning imaginative prompts from kids—such as “write a story about a dog and a cat”—into coherent, code-based stories. Remarkably, these stories are generated using relevant Tynker code blocks, even though they were never part of our original training set. This showcases the model’s ability to leverage its pre-trained knowledge to create engaging narratives in Tynker’s unique block coding environment!
Prompt: “write a story about a dog and a cat”
Response:

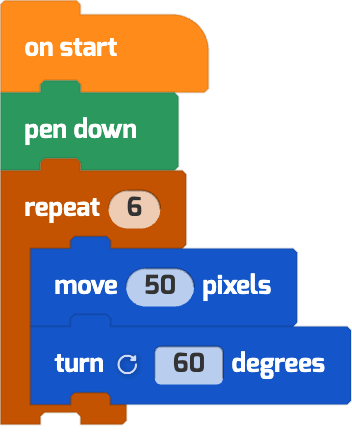
Our model doesn’t just stop at storytelling; it excels in executing precise tasks as well. For instance, when given the prompt “draw a size 50 hexagon,” the model skillfully generates code that results in a perfect six-sided shape. It turns 60 degrees clockwise and moves 50 pixels to create each side, closing the shape with impeccable accuracy.
Prompt: draw a size 50 hexagon
Response:
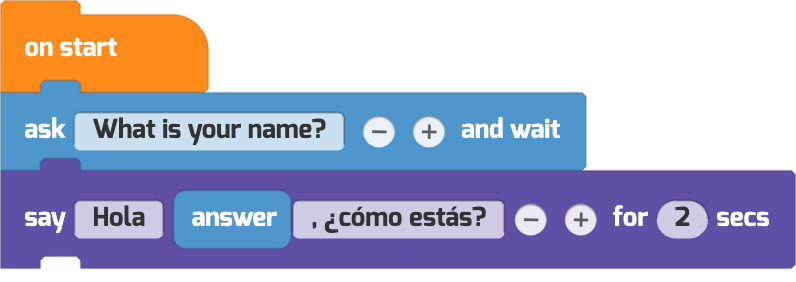
Leveraging the Base Model’s capabilities, our model also excels in multilingual tasks. For example, when prompted to “ask for my name and say ‘hello name, how are you?’ in Spanish,” the model astutely generates code that asks for the user’s name in English and responds in flawless Spanish.
Prompt: ask for my name and say “hello name, how are you?” in spanish
Response:
The Future is Bright
We’re just getting started. From delving into the realms of Physics and Minecraft modding to exploring uncharted territories, the future holds endless possibilities for innovation at Tynker.
Code Explanation Made Easy
We’re pioneering new features in our code editor, such as the “Explain Code” function. With a simple right-click on a code snippet, students can instantly understand what each block of code accomplishes, even if they’re new to Tynker’s block language.
Tutorial Generation: Tailored Learning Experiences
Our aim is to create a model that can teach kids how to build projects they’re passionate about, without simply handing them the completed code. With thousands of tutorials in our repository, we’re well on our way to offering personalized, guided learning experiences.
Debugging on the Fly: A Revolutionary Approach
We’ve also developed a streaming syntax-correcting parser, allowing kids to see visual blocks generated in real-time as the model processes tokens. Coupled with a chat-style interface, this enables children to interact with their coding copilot using natural language, making coding more intuitive than ever.
In Conclusion: The Future of Tynker Copilot
As we continue to innovate, our vision for Tynker Copilot is clear: seamless integration within Tynker’s existing coding environment. But our mission goes beyond mere convenience; we aim to create a tool that genuinely aids in the learning process. To that end, we’re committed to ensuring that Tynker Copilot assists without enabling cheating, a balance that our team is diligently working to achieve.
Student safety and privacy are cornerstones of our development process. We’re taking proactive measures to ensure that the code generated avoids risky, violent, or unsafe topics. This aligns with our unwavering commitment to providing a secure and educational coding environment for kids.
So, as we look to the future, we’re excited about the endless possibilities that Tynker Copilot will bring to young coders around the world. Stay tuned for more updates as we continue to fine-tune this groundbreaking innovation!




{kind=link}